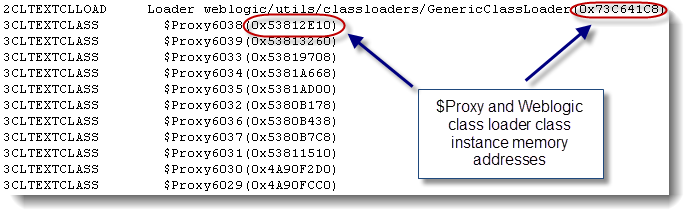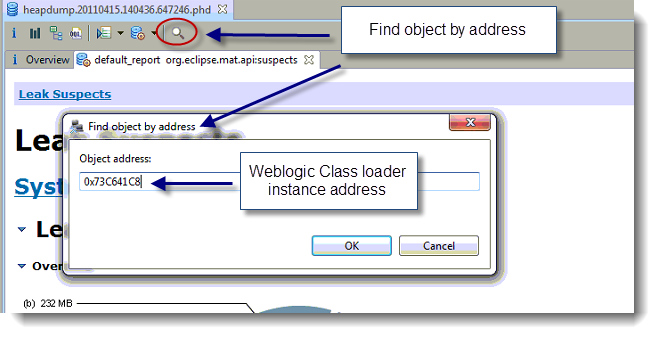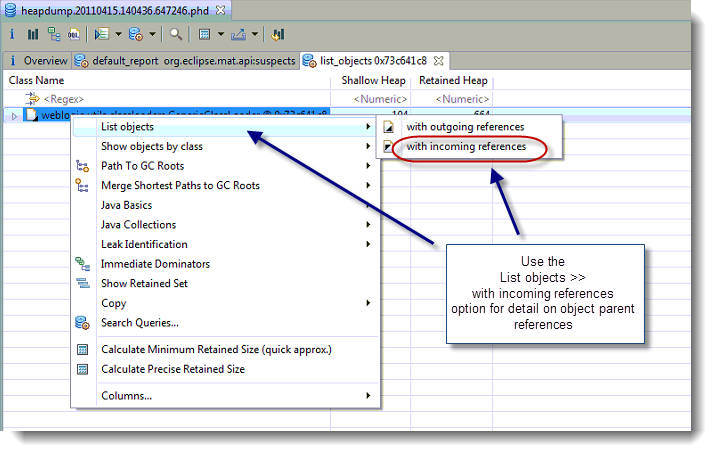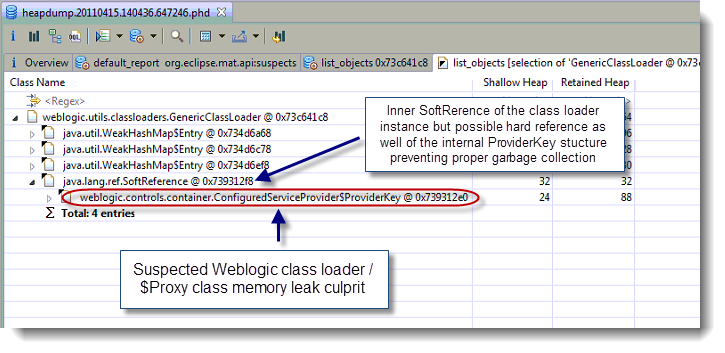



This article will provide you a detailed explanation on how you can identify, resolve and prevent Thread hang problems involved in a java.net.socketinputstream.socketread0 blocking IO operation.
Background

Proper understanding of these concepts is quite important when developing and supporting a Java EE production system since lack of proper timeout and understanding will eventually bring your system to its knees via Thread depletion.
Background
Modern Java EE production systems usually rely heavily on remote service providers for its various business processes. Such service providers are referred as downstream systems. For example: you may need to pull your client account data from an Oracle database or consume a remote Web Service SOAP/XML data. Regardless of the protocol used (HTTP, HTTPS. JDBC etc.) the Java VM will eventually be requested to establish a Socket connection from your production server to the remote service provider environment and then write / read data to / from the Socket. This process is referred as a “blocking IO call”.
The Thread involved in this blocking IO call can get hang for either:
· Socket.connect() operation (establish a new physical connection between your production server and your remote service provider such as an Oracle database listener, a Web Service URL etc.)
· Socket.write() operation (send the data to the service provider such as a database query request / SQL, an XML request data etc.)
· Socket.read() operation (wait for the service provider to complete its processing and consume the response data such as results of a database SQL query or an XML response data)
The third operation is what we will cover today.
In order to better help you visualize this process, find below a high level graphical view of the different operations and interactions:
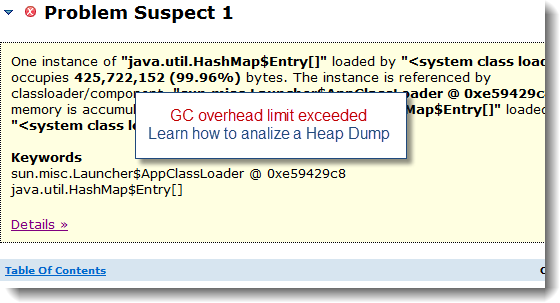
Problem identification: JVM Thread Dump to the rescue!
Generating a JVM Thread Dump is the best and fastest procedure to quickly pinpoint the source of the slowdown and identify which Socket operation is hanging. The example below is showing you a JBoss Thread hanging in a Socket.read() operation triggered from a Web Service HTTPS call. You can also refer to this JBoss problem post for the complete case study and root cause analysis.
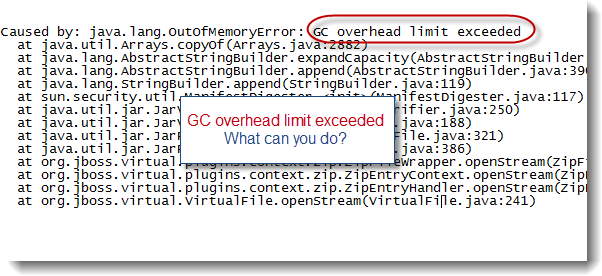
The first line of the Thread Stack trace will always show you which type of Socket operation is hanging.
"http-0.0.0.0-8443-102" daemon prio=3 tid=0x022a6400 nid=0x1bd runnable [0x78efb000]
java.lang.Thread.State: RUNNABLE
at java.net.SocketInputStream.socketRead0(Native Method)
at java.net.SocketInputStream.read(SocketInputStream.java:129)
at com.sun.net.ssl.internal.ssl.InputRecord.readFully(InputRecord.java:293)
at com.sun.net.ssl.internal.ssl.InputRecord.read(InputRecord.java:331)
at com.sun.net.ssl.internal.ssl.SSLSocketImpl.readRecord(SSLSocketImpl.java:789)
- locked <0xdd0ed968> (a java.lang.Object)
at com.sun.net.ssl.internal.ssl.SSLSocketImpl.readDataRecord(SSLSocketImpl.java:746)
at com.sun.net.ssl.internal.ssl.AppInputStream.read(AppInputStream.java:75)
- locked <0xdd0eda88> (a com.sun.net.ssl.internal.ssl.AppInputStream)
at java.io.BufferedInputStream.fill(BufferedInputStream.java:218)
at java.io.BufferedInputStream.read1(BufferedInputStream.java:258)
at java.io.BufferedInputStream.read(BufferedInputStream.java:317)
- locked <0xddb1f6d0> (a java.io.BufferedInputStream)
at sun.net.www.http.HttpClient.parseHTTPHeader(HttpClient.java:687)
at sun.net.www.http.HttpClient.parseHTTP(HttpClient.java:632)
at sun.net.www.http.HttpClient.parseHTTP(HttpClient.java:652)
at sun.net.www.protocol.http.HttpURLConnection.getInputStream(HttpURLConnection.java:1072)
- locked <0xdd0e5698> (a sun.net.www.protocol.https.DelegateHttpsURLConnection)
at java.net.HttpURLConnection.getResponseCode(HttpURLConnection.java:373)
at sun.net.www.protocol.https.HttpsURLConnectionImpl.getResponseCode(HttpsURLConnectionImpl.java:318)
at org.jboss.remoting.transport.http.HTTPClientInvoker.getResponseCode(HTTPClientInvoker.java:1269)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:802)
………………………………………………………………………………………………
Root cause and resolution
As seen in the above diagram, the most common scenario for a hanging Socket.read() is a high processing time or unhealthy state of your remote service provider. This means that you will need to communicate with the service provider support team right away in order to confirm if they are facing some slowdown condition on their system.
Your applicaton server Threads should be released once the remote service provider system problem is resolved but quite often you will need to restart your server instances (Java VM) to clear all the hanging Threads; especially if you are lacking proper timeout implementation.
Other less common causes include:
- Huge response data causing increased elapsed time to read / consume the Socket Inputstream e.g. such as very large XML data. This can be proven easily by analysing the size of the response data
- Network latency causing increased elapsed time in data transfer from the service provider to your Java EE production system. This can be proven by running some network sniffer between your production server and the service provider and determine any major lag/latency problem
Problem prevention: timeout implementation!
Too many Thread hanging in a IO blocking calls such as Socket.read() can lead to a rapid Thread depletion and full outage of your production enviroment, regardless of the middle ware vendor you are using (Oracle Weblogic, IBM WAS, Red Hat JBoss etc,.).
In order to prevent and reduce the impact of such instability of your service providers, the key solution is to implement proper timeout for all 3 Socket operations. Implementation and validation of such timeout will allow you to cap the number of time you are allowing the application server Thread to wait for a particular the Socket operation. Most modern communication APIs today allow you to setup such timeout fairly easily.
I also recommend that you perform negative testing in order to simulate such service provider instability / slowdown. This will ensure that your timeouts are working properly and that your production system will be able to survive during these negative scenarios.
Conclusion
I hope this article has helped you better understand the source and root cause of these hang Threads that you see in your environment and how to analyse and take some corrective actions. My next article will provide you with more detail on timeout implementations and methods available from various communication APIs.
Please don't hesitate to add a comment or email me if you still have questions or doubts on this type of problem.